Du startest deinen KI-Agenten und sagst: „Mach mir einen LinkedIn-Post." Eine Minute später kommt etwas zurück, das nach generischer Standard-KI klingt – nicht nach dir, nicht nach deinem Business, nicht nach deinen Kunden. Du seufzt, schreibst um, fragst dich, warum der ganze KI-Hype dir nichts bringt.
Die Antwort ist unbequem ehrlich: Der Agent kennt dich nicht. Er kann es auch nicht. Ein KI-Agent ist ein extrem fähiger, aber radikal kontextloser Mitarbeiter. Wenn du ihm keinen Kontext gibst, liefert er Standard.
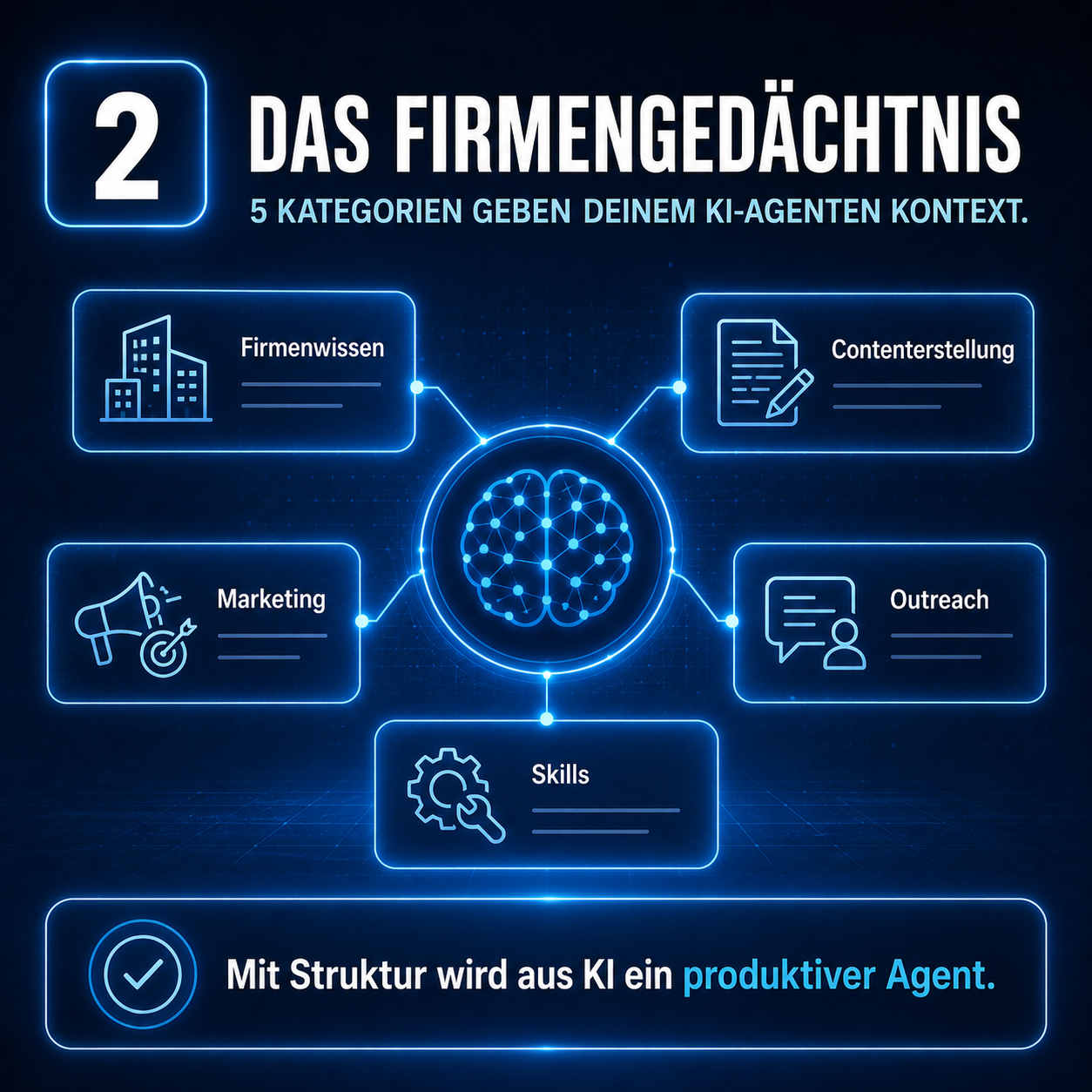
Die Lösung heißt Firmengedächtnis – eine strukturierte Wissensdatenbank, die jeder Agent vor dem Arbeiten liest. Bei uns reichen dafür fünf Kategorien. Wie sie aussehen, was reingehört, warum wir es als Git-Repository pflegen und nicht in Notion – das ist der Inhalt der nächsten zehn Minuten.
Inhaltsverzeichnis
1. Das Problem: Dein Agent weiß nichts über dich
Jeder neue Chat mit Claude, ChatGPT oder OpenClaw startet bei null. Der Agent weiß nicht, wer du bist, welche Branche, welche Zielgruppe, welchen Tonfall du benutzt, was deine Mandanten wirklich zahlen, welche Wettbewerber dich nerven. Er kann es nicht wissen, du hast es ihm ja nie gesagt.
Die übliche Reaktion: Du erklärst es jedes Mal neu. „Ich bin Berater für…", „meine Zielgruppe ist…", „Tonfall ist du, nicht Sie…". Nach dem dritten Mal hast du keine Lust mehr. Du tippst hastig, der Output wird generisch, du frustrierst dich.
Dein KI-Agent kann nur so gut sein wie sein Firmengedächtnis.
Das Frustgefühl ist nicht ein Indiz für schlechte KI. Es ist ein Indiz für fehlende Struktur. Und genau diese Struktur kannst du einmal bauen – und dann immer wieder benutzen.
2. Die Lösung: Ein Firmengedächtnis
Ein Firmengedächtnis ist eine strukturierte Wissensdatenbank im Markdown-Format, die jeder Agent vor dem Arbeiten liest. Keine Datenbank, kein hippes SaaS-Tool – einfach Textdateien in einer übersichtlichen Ordnerstruktur, idealerweise versioniert in einem Git-Repository.
Der Charme des Konzepts: Es funktioniert mit jedem KI-Werkzeug. Claude liest die Dateien direkt, ChatGPT kann sie als Kontext bekommen, OpenClaw liest sie nativ aus dem Repo. Kein Vendor-Lock-In, kein Wechsel-Drama, wenn du in zwei Jahren auf das nächste Tool umsteigst.
📌 Warum gerade Markdown?
Markdown ist Klartext mit minimaler Formatierung. Menschen können es lesen und schreiben, KI-Tools können es nativ parsen ohne API. Es funktioniert in jedem Editor, lässt sich versionieren und sieht auch in zehn Jahren noch genauso aus wie heute. Notion-Datenbanken haben in zehn Jahren vielleicht eine andere API – Markdown-Dateien nicht.
Das Konzept ist nicht ganz neu – es ist eine Adaption des aus der LLM-Community bekannten „Wiki-für-den-Agent"-Patterns. Wir haben es für Solo-Gründer-Bedürfnisse zugeschnitten: weniger akademisch, dafür mit konkretem Fokus auf wiederkehrende Beratungs- und Content-Workflows.
3. Die fünf Kategorien im Detail
Diese fünf Kategorien decken in unserer Beratungspraxis alle relevanten Kontextarten ab. Du brauchst nicht alle fünf am ersten Tag – iterativ aufbauen ist die Devise – aber wenn alle stehen, hat dein Agent praktisch immer den richtigen Kontext.
Wer bist du, was machst du?
Die Basis. Wird vor jeder neuen Aufgabe gelesen, ohne diesen Kontext ist alles andere Stückwerk.
team.md
tools-stack.md
markenstimme.md
Wie produziert ihr Content?
Pro Plattform ein eigenes Briefing mit Aufbau, Tonalität, Killer-Phrasen, Stilreferenzen aus echten Posts.
tiktok-briefing.md
blog-briefing.md
linkedin-beispiele.md
Strategische Entscheidungen
Zielgruppen, Positionierung, Wettbewerb, Performance-Werte aus der Vergangenheit. Was funktioniert, was nicht.
positionierung.md
wettbewerber.md
performance-tracking.md
Wie sprichst du Menschen an?
Templates, Kunden-Originalzitate, Einwandbehandlung. Hier kommt die echte Stimme deiner Mandanten rein.
cold-outreach.md
kunden-feedback.md
objection-handling.md
Wiederverwendbare Workflows
Das ist die mächtigste Kategorie. Hier liegen einzelne „Mitarbeitervertrage" für deine Agenten – jede Skill-Datei beschreibt einen Workflow so präzise, dass der Agent ihn eigenständig ausführen kann.
skills/finanzplan-review.md
skills/wettbewerbs-briefing.md
skills/blog-article-creator.md
Pro Kategorie reichen am Anfang drei bis fünf Dateien. Es ist nicht das Ziel, alles am ersten Tag zu dokumentieren. Du fängst mit dem Basis-Kontext an (Kategorie 1), ergänzt iterativ je nachdem, welche Aufgaben du als nächstes delegieren willst.
Dieser Artikel ist selbst ein Beweis fürs Konzept: Geschrieben wurde er von einer Claude-Code-Session, die auf ein internes Skill-Setup mit genau dieser Struktur zugreift. Darin liegen Dateien wie brand.md, components.md, workflow.md und eine seo-checklist.md – die dem Agent sagen, in welchem Stil, mit welchen HTML-Bausteinen und nach welchen EEAT-Standards er einen Artikel zu bauen hat. Ohne diese Vorarbeit hätte derselbe Artikel das Doppelte an Korrekturen gebraucht.
4. Warum Git-Repository statt Notion?
Die häufigste Rückfrage in unseren Erstgesprächen: „Wir haben doch schon Notion – warum nicht das nutzen?" Berechtigt. Hier die ehrliche Gegenüberstellung.
| Kriterium | Git-Repository (Markdown) | Notion / vergleichbares SaaS |
|---|---|---|
| Lesbar für KI | ✓ nativ, kein API-Aufruf nötig | über API möglich, fragil |
| Versionierung | ✓ jede Änderung dokumentiert | begrenzt, kostenpflichtig |
| Vendor-Lock-In | ✓ keiner, Markdown ist universal | ✗ Notion-spezifische Strukturen |
| Kosten | ✓ kostenlos (GitHub Free) | ab 10 €/Monat pro User |
| Datenschutz / Hosting | ✓ self-hostbar (Gitea, GitLab) | US-Hosting, Drittland |
| Visuelle Bedienung | Editor nötig, weniger eingängig | ✓ WYSIWYG, Drag & Drop |
| Team-Bedienbarkeit | Git-Grundlagen nötig | ✓ niedrige Hürde |
Unser Fazit aus der Praxis: Wenn die KI-Lesbarkeit zählt, gewinnt Git. Wenn die menschliche Bequemlichkeit für ein nicht-techaffines Team zählt, gewinnt Notion. Es gibt auch einen Mittelweg – kritische Skill-Dateien als Markdown im Git, allgemeine Wissens-Doku in Notion. Aber für Solo-Gründer mit etwas Tech-Affinität ist das Git-Setup nach einer eingearbeiteten Stunde stabiler und langfristig billiger.
5. In fünf Schritten starten
Du musst nicht alles am ersten Tag aufsetzen. Hier der pragmatische Pfad, mit dem unsere Mandant:innen typischerweise in einer Woche zur produktiven Erstversion kommen.
Repository anlegen (15 Minuten)
GitHub-Account erstellen (kostenlos), neues privates Repository „firmengedaechtnis" anlegen, lokal klonen.
git clone https://github.com/<dein-user>/firmengedaechtnis.git
cd firmengedaechtnis
Ordnerstruktur anlegen (5 Minuten)
firmengedaechtnis/ ├── 1-firmenwissen/ ├── 2-content/ ├── 3-marketing/ ├── 4-outreach/ └── 5-skills/
Mit firmenkontext.md starten (45 Minuten)
Erstmal nur diese eine Datei. Wer bist du, was bietest du, wer ist deine Zielgruppe, welche Tools nutzt du, welche Tonalität pflegst du. Das ist der Anker – alle anderen Dateien bauen darauf auf.
Eine Skill-Datei für den schmerzhaftesten Workflow (1 Stunde)
Wähle aus, was dich pro Woche am meisten Zeit kostet. Bei den meisten Mandant:innen ist das die E-Mail-Triage oder das wöchentliche Wettbewerbs-Briefing. Schreibe dafür eine skill/triage.md, die so präzise ist, dass ein guter Junior-Mitarbeiter sie umsetzen könnte. Dann kann es auch die KI.
Mit dem Agent testen und iterieren (laufend)
Bei Claude Code: cd firmengedaechtnis && claude – fertig, der Agent liest die Dateien automatisch. Bei ChatGPT/OpenClaw: relevante Dateien als Kontext mitgeben. Wichtig: Bei Fehlern korrigierst du nicht den Output, sondern das Briefing. So lernt das System dauerhaft, nicht jedes Mal aufs Neue.
💡 Realistischer Aufwand
Die initiale Version steht in einem konzentrierten Nachmittag – etwa zwei bis drei Stunden. Der echte Wert kommt aber durchs Iterieren. Nach vier Wochen produktiver Nutzung ist dein Firmengedächtnis besser als jede Beratungs-Slide-Deck, weil es genau die Patterns enthält, die in DEINEM Business funktionieren.
6. Fünf häufige Fehler beim Aufbau
Die fünf Fehler, die wir bei Mandant:innen am häufigsten sehen – und wie du sie vermeidest.
⚠ Was dein Firmengedächtnis NICHT enthalten sollte
Keine echten Mandantendaten, keine Passwörter, keine personenbezogenen Daten, die du in zwei Jahren nicht mehr verarbeiten darfst. Pseudonymisiere konsequent. Die Skills selbst – die Workflow-Beschreibungen – enthalten keine Personendaten. Sie sind reine Anleitung. Das ist auch der Grund, warum manche Mandant:innen ihr Firmengedächtnis sogar öffentlich machen: weil dort kein Geheimnis drinsteht.
7. Wie eine reale Skill-Datei aussieht
Damit du nicht vor leerer Datei sitzt, hier die Struktur eines real genutzten Skills aus unserer Beratungspraxis (Kategorie 5 – „Skills"). Es ist nicht der einzig richtige Aufbau, aber einer, der bei uns seit Wochen funktioniert.
# Beispiel: skill-blog-article-creator/ SKILL.md # Drehscheibe – wann wird Skill ausgelöst? brand.md # Farben, Fonts, Tonalität, Author-Standard components.md # HTML-Bausteine (z.B. Stat-Card, CTA) workflow.md # 11-Schritt-Prozess vom Briefing zum PR seo-checklist.md # Pflichtelemente + EEAT-Anforderungen image-generation.md # Hero-Bilder via API oder Stock examples/ # Pointer zu Referenz-Artikeln
Pro Datei reicht eine Seite Inhalt, oft weniger. Wichtig ist nicht die Länge, sondern die Klarheit: Welche Entscheidungen muss der Agent treffen, und welche Standards gelten?
Diese Struktur ist auf businessstart.eu zugeschnitten – nicht universell. Genau das ist der Punkt: Dein Firmengedächtnis muss zu dir passen, nicht zu einem Template. Wenn du den Starter konkret für dein Business durchsprechen willst, dazu im nächsten Block mehr.
Quellen & weiterführende Links
Die in diesem Artikel zitierten Konzepte und Tools sind gegen folgende Original-Quellen geprüft:


