Du sammelst Sprachnotizen. Auf dem Weg zur Bahn, beim Spaziergang, im Auto. Aber dann landen sie in einer App, werden vielleicht transkribiert, und kein KI-Agent macht etwas damit. Die Brücke zwischen Sprach-Input und konkretem Output fehlt – und genau die füllt dieser Artikel.
Wir zeigen dir, wie du dir mit Hermes Agent (Nous Research, Open Source), DeepSeek V4 als günstigem Sprachmodell und einem Hetzner-VPS für rund 4 € im Monat einen Voice-First-Agenten baust, der deine Sprachnachrichten in deinem GitHub-Repository ablegt, recherchiert und auf Zuruf das Firmengedächtnis durchsucht. Mit ehrlichen Kosten, transparenten Limitationen und einer klaren Abgrenzung zu ChatGPT Voice.
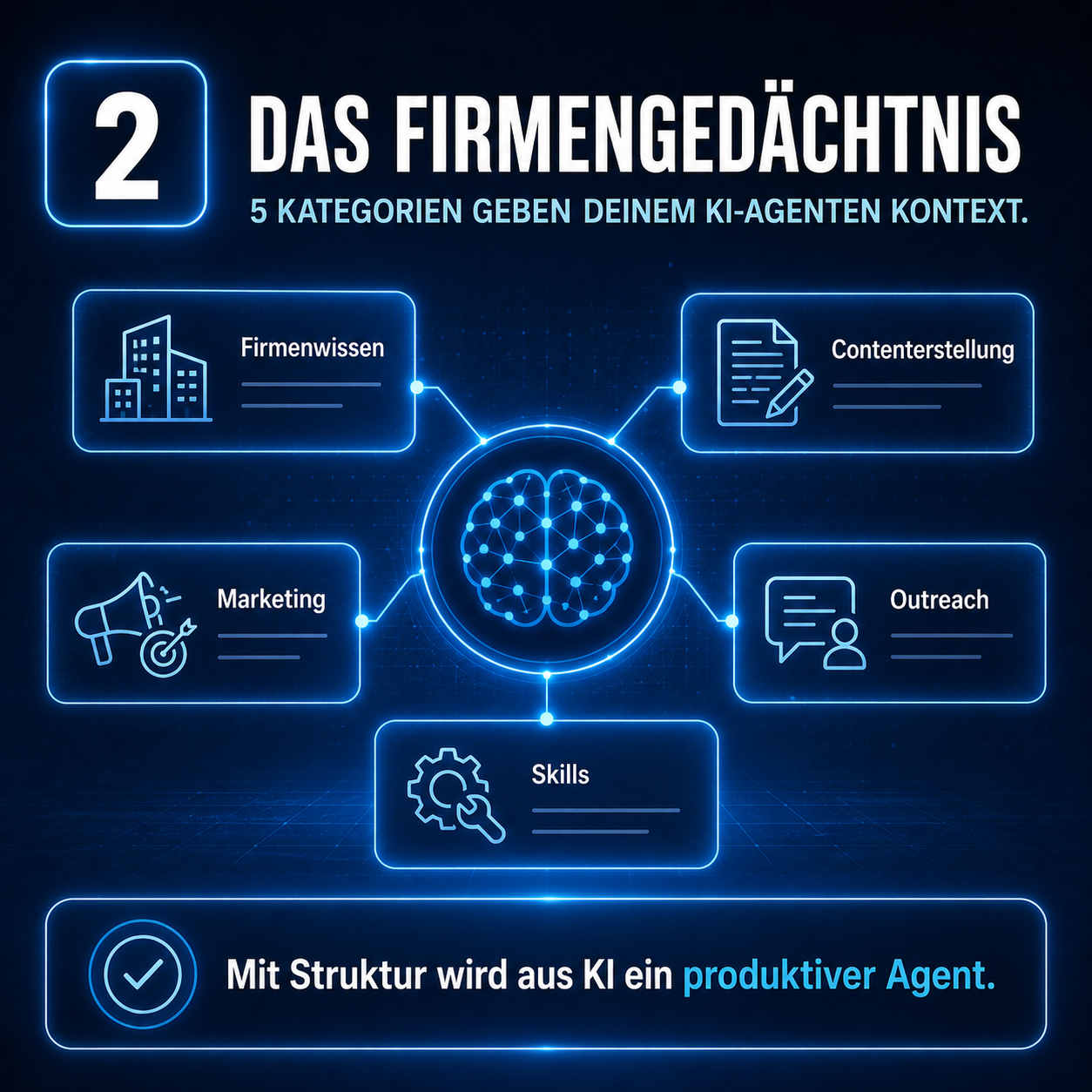
Wenn du noch nicht weißt, warum man überhaupt mehrere KI-Agenten parallel laufen lässt, lies vorher unsere vier Wege im ehrlichen Vergleich. Und wenn dir das Konzept „Firmengedächtnis" noch fremd ist, fang mit der Übersicht der fünf Kategorien an. Hier wird's konkret.
Inhaltsverzeichnis
- Das Problem, das niemand löst
- Die Architektur in einem Diagramm
- Drei Use Cases, mit denen du heute startest
- Warum Hermes – und warum nicht OpenClaw
- Warum DeepSeek V4 – und der Modell-Routing-Trick
- Die Setup-Schritte in fünf Phasen
- Die echten Kosten – transparent
- Was funktioniert gut – und was nicht
- Der Unterschied zu ChatGPT Voice
- Konkrete erste Schritte
1. Das Problem, das niemand löst
Wer Beratung oder Gründung macht, hat täglich gute Gedanken auf dem Weg. Beim Kaffee, im Bus, nach dem Mandantengespräch. Die meisten landen in einer Notiz-App, manche in einer Voice-Memo-Aufnahme. Die Hoffnung: „Ich kümmere mich später drum."
Das Später kommt selten. Voice-Memos liegen in der App, Transkriptionen werden nicht weiterverarbeitet, der gute Gedanke versickert. Solo-Gründer:innen verlieren so jeden Tag Substanz, die nie wieder hochkommt. Das ist nicht „Disziplin"-Problem, das ist ein Werkzeug-Problem.
Eine Sprachnachricht im Vorbeigehen muss zu einem Eintrag im Firmengedächtnis werden – ohne Umweg über zehn Apps.
Was wir brauchen: einen Agenten, der die Sprachnachricht entgegennimmt, transkribiert, versteht, klassifiziert und ins richtige Verzeichnis im Firmengedächtnis schreibt. Wenn ich frage „Was hatte ich letzte Woche zum Hochschul-Partnerprogramm überlegt?", soll er es wiederfinden und auf Deutsch antworten. Genau das bauen wir heute.
2. Die Architektur in einem Diagramm
Bevor wir in die Schritte gehen, der visuelle Überblick. Sechs Bausteine, drei davon kostenlos.
Der Clou ist die untere Hälfte: Statt jede Anfrage über das teure Claude-Opus-Modell laufen zu lassen, routet Hermes 90 Prozent der Aufgaben auf DeepSeek V4 (sehr günstig) und nur die qualitätssensiblen 10 Prozent auf Claude Sonnet. Mehr dazu in Sektion 5.
3. Drei Use Cases, mit denen du heute startest
Bevor wir Setup-Schritte aufzählen, hier drei konkrete Workflows aus der eigenen Beratungspraxis. Das ist, was du am Ende tatsächlich tun wirst – nicht abstrakte „Möglichkeiten".
1 Notiz speichern per Voice
Eine Idee oder Beobachtung wandert direkt ins Firmengedächtnis – mit Git-Commit. Versioniert, durchsuchbar, niemals verloren.
Was passiert: Whisper transkribiert. Hermes klassifiziert (Idee / Aufgabe / Kunden-Notiz) und legt sie in der passenden Datei ab. Commit-Message wird automatisch generiert.
2 Recherche-Auftrag per Voice
Async im Hintergrund: Du fragst, gehst in den Termin, beim Rauskommen liegt der strukturierte Bericht im Firmengedächtnis.
Was passiert: Web-Search-Tool läuft, Hermes synthetisiert, legt einen Bericht im Firmengedächtnis ab und schickt dir eine Voice-Zusammenfassung zurück.
3 Firmengedächtnis abfragen
Der eigentliche Game-Changer. Du hast etwas notiert, weißt aber nicht mehr genau wann. Voice-Frage genügt.
Was passiert: Hermes durchsucht die Markdown-Dateien im Firmengedächtnis, findet relevante Einträge der letzten 14 Tage, antwortet auf Deutsch mit Quellen-Verweis auf die jeweilige Datei.
4. Warum Hermes – und warum nicht OpenClaw
Beide sind Open-Source-Multi-Agent-Frameworks, beide laufen auf deinem eigenen VPS. Wir haben sie im großen Vergleichsartikel ausführlich gegenübergestellt, dort wird auch klar: OpenClaw ist architektonisch reifer, Hermes ist funktional moderner. Für den Voice-First-Use-Case kippt die Entscheidung zugunsten Hermes – und das hat einen konkreten Grund.
Hermes ist Voice-First-tauglich „out of the box"
Laut offizieller Hermes-Doku werden Sprachnachrichten in Telegram, Discord, WhatsApp, Slack und Signal automatisch transkribiert und als Text in die Konversation eingefügt – ohne dass du irgendwelche Plugins konfigurieren musst. Voice-Antworten kommen als native Telegram-Voice-Bubbles zurück (also die runden, inline-abspielbaren). Mit der gratis Edge-TTS-Stimme funktioniert das ohne API-Key. Wer Premium-Stimmen will, hängt OpenAI-TTS oder ElevenLabs dran.
OpenClaw hat aktuell einen dokumentierten Telegram-Voice-Bug
Im Februar 2026 wurde Issue #17101 im offiziellen OpenClaw-Repo aufgemacht: Telegram-Voice-Nachrichten (`.ogg` mit Opus-Codec) kommen zwar an, werden aber nicht automatisch transkribiert. Stattdessen sieht der Agent rohes `
📌 Klarstellung: keine generelle Wertung
OpenClaw bleibt für viele andere Use Cases die solidere Wahl – fünf Jahre Reife, größere Audit-Tiefe, robuste Sandbox-Architektur. Aber für Voice-First mit Telegram ist Hermes 2026 die pragmatischere Entscheidung.
5. Warum DeepSeek V4 – und der Modell-Routing-Trick
Ein KI-Agent ist nur so teuer wie das Modell, das er verwendet. Hier kommt der größte Hebel: nicht alles muss über Claude Opus laufen. DeepSeek V4 leistet für 90 Prozent der Aufgaben (Transkription verstehen, klassifizieren, ablegen, einfache Recherche-Anfragen) qualitativ vergleichbar – zu einem Bruchteil der Kosten.
Die offiziellen Preise (Stand Mai 2026, laut DeepSeek API Docs und Anthropic Pricing):
| Modell | Input (cached) | Input (uncached) | Output |
|---|---|---|---|
| DeepSeek V4 Pro (Promo bis 31.05.26) | $0,0036 / M | $0,435 / M | $0,87 / M |
| Claude Sonnet 4.6 | ~$0,30 / M | $3 / M | $15 / M |
| Claude Opus 4.7 | $0,50 / M | $5 / M | $25 / M |
Bei gecachtem Input ist DeepSeek V4 Pro derzeit etwa 140-fach günstiger als Claude Opus 4.7. Bei nicht-gecachtem Input immer noch etwa 11-fach günstiger. Das ist keine Optimierung, das ist eine andere Größenordnung – und genau das macht 100 parallele Agenten oder einen den ganzen Tag laufenden Voice-Agenten finanzierbar.
💡 Modell-Routing-Faustregel
90 % der Aufgaben: DeepSeek V4 (Transkriptions-Verstehen, Klassifikation, einfache Recherche). 10 % qualitätskritisch: Claude Sonnet (Strategie-Texte, juristisch relevante Inhalte, Kunden-Kommunikation). Nahe null Prozent auf Opus: nur Sonderfälle mit echtem Reasoning-Bedarf.
⚠ Promo-Pricing-Hinweis
Die DeepSeek-V4-Pro-Cache-Preise sind laut offizieller Preisseite eine Promo bis zum 31. Mai 2026. Danach steigen die Listenpreise (auf $1,74 / M cache-miss-input, $3,48 / M output). Auch nach dem Promo-Ende bleibt DeepSeek deutlich günstiger als Claude – aber nicht mehr im Faktor-100-Bereich. Plane Modell-Routing trotzdem ein.
6. Die Setup-Schritte in fünf Phasen
Wenn du am Wochenende loslegst, schaffst du Phase 0 und 1 in zwei Stunden. Die anderen Phasen sind Tagesthemen, keine Wochenend-Marathons.
Phase 0: Hermes vorab ausprobieren (10 Min)
Bevor du einen VPS einrichtest, teste Hermes im gehosteten Modus auf der Nous-Research-Website. Kostet ein paar US-Dollar für die ersten Stunden, gibt dir aber ein Bauchgefühl, ob das Konzept zu deinem Workflow passt.
Phase 1: Hetzner-VPS aufsetzen (45 Min)
Auf console.hetzner.cloud: neuer Server CX22 (ca. 4 €/Monat), Ubuntu 24.04, Standort Nürnberg oder Falkenstein, SSH-Key. Danach Node.js, Docker, ufw-Firewall installieren.
ssh root@<ip-adresse> apt update && apt upgrade -y apt install -y nodejs npm git docker.io ufw ufw allow OpenSSH && ufw enable
Phase 2: Hermes installieren (30 Min)
Per offizieller Anleitung der Hermes-Doku. Konfiguration in ~/.hermes/config.yaml, API-Keys für DeepSeek und optional Anthropic in `.env` ablegen (nicht ins Repo!).
Phase 3: Telegram-Bot konfigurieren (15 Min)
Bei Telegrams @BotFather einen neuen Bot anlegen, Token erhalten, in Hermes-Config eintragen. Voice-Mode ist laut Doku per Default aktiv – kein extra Plugin nötig. Whisper läuft lokal (faster-whisper, ~150 MB Download).
Phase 4: GitHub-Token einbinden (10 Min)
Auf GitHub einen fine-grained Personal Access Token erstellen, der nur auf dein Firmengedächtnis-Repo Schreibrechte hat. Token in `.env` ablegen. Im Hermes-Skill ein Tool `github_commit` definieren.
Phase 5: Erste Skills schreiben (60 Min)
Pro Use Case eine Markdown-Skill-Datei (siehe unsere Firmengedächtnis-Struktur – Kategorie 5 „Skills"). Skill „notiz-speichern", „web-recherche", „firmengedaechtnis-abfragen". Iterativ testen und nachschärfen.
Beim ersten Setup haben wir in der eigenen Beratungspraxis nicht – wie versprochen – zwei Stunden gebraucht, sondern einen ganzen Samstag. Der Stolperstein: GitHub-Token wurden mit zu breiten Rechten erstellt („contents:write" auf ALLE Repos statt nur eines), wir mussten zurück, fine-grained Token nachziehen, dann erst lief der Commit-Flow stabil. Empfehlung: Token-Berechtigungen so eng wie möglich – das spart später Audit-Stress, wenn man dem System sensible Inhalte anvertraut.
— Tobias Späth, Mai 20267. Die echten Kosten – transparent
Zwei realistische Szenarien. Solo-Gründer mit moderater Nutzung kommen unter 30 €/Monat, wer Premium-Voice will, landet bei rund 60 €.
| Komponente | Minimal (gratis-TTS) | Premium (ElevenLabs-TTS) |
|---|---|---|
| Hetzner CX22 VPS | 4 € | 4 € |
| DeepSeek V4 Pro API (ca. 90 % der Tasks) | 10–15 $ | 10–15 $ |
| Claude Sonnet (Qualitäts-Routing) | 5–10 $ (optional) | 5–10 $ |
| Whisper (Sprache → Text) | 0 € (lokal via faster-whisper) | ~5 $ (OpenAI API) |
| TTS (Text → Sprache) | 0 € (Edge-TTS gratis) | 5–22 $ (ElevenLabs) |
| Telegram Bot | 0 € | 0 € |
| Gesamt pro Monat | ~20–35 € / $ | ~45–60 € / $ |
Zum Vergleich: Dasselbe Setup mit Claude Opus als Daily Driver würde 100–200 € pro Monat kosten. Der Faktor liegt also im Modell-Routing, nicht im Framework.
8. Was funktioniert gut – und was nicht
Was wirklich gut funktioniert
- Deutsche Voice-Eingabe via Telegram: Whisper unterstützt laut Hermes-Doku zahlreiche Sprachen, deutsche Erkennung ist sehr stabil, auch mit Umgangssprache und Dialekt-Einschlag
- Async-Workflow: Du schickst eine Nachricht, gehst in den Termin, Antwort liegt nachher im Telegram
- Modell-Routing: Hermes kann pro Skill ein anderes Modell definieren – sauber konfigurierbar
- GitHub-Schreibzugriff: Commit-Messages werden automatisch sinnvoll generiert, Versionierung ist gratis dabei
- Privacy: Daten liegen auf deinem VPS und in deinem Repo, nicht bei einem US-Hyperscaler (sofern du europäisches Hosting wählst)
Was Du wissen musst
- Latenz: 10–30 Sekunden pro Austausch – kein flüssiges Gespräch wie bei ChatGPT Advanced Voice. Eher wie WhatsApp-Voice-Memos zurück und vor
- TTS-Qualität bei der gratis Edge-TTS: klingt etwas roboterhaft. Wer „natürliche Stimme" braucht, muss ElevenLabs zubuchen
- Reifegrad von Hermes: drei Monate alt (seit Februar 2026), weniger Code-Review-Augen als bei OpenClaw. Bugs sind möglich
- Wartung: Linux-Updates, Hermes-Updates, Token-Rotation – das passiert nicht von alleine
9. Der Unterschied zu ChatGPT Voice
OpenAI hat im Mai 2026 mit GPT-Realtime-2 eine sehr beeindruckende neue Generation an Voice-Modellen vorgestellt. Sub-Sekunden-Latenz, GPT-5-Class-Reasoning, natürliche Stimmen, flüssige Konversation. Laut offizieller OpenAI-Ankündigung ist es das aktuell führende Voice-Modell.
Die Kosten allerdings: $32 pro Million Audio-Input-Tokens, $64 pro Million Audio-Output-Tokens. Da Audio Token nach Dauer berechnet werden (Eingabe ca. 1 Token / 100 ms, Ausgabe 1 Token / 50 ms), kommt man laut Praxis-Analysen auf typische Real-Kosten zwischen 0,18 $ und 0,46 $ pro Minute. Eine intensive Stunde am Tag kostet damit 5–15 $, im Monat 150–450 $.
| Kriterium | Hermes + DeepSeek | GPT-Realtime-2 |
|---|---|---|
| Latenz | 10–30 Sek | Sub-Sekunden |
| Konversationsfluss | asynchron (Voice-Memo) | flüssig wie Telefonat |
| Eigenes Firmengedächtnis lesen/schreiben | ja, direkt | nur über Tools |
| Kosten/Monat (moderate Nutzung) | ~25–35 € | ~150–450 $ |
| Datenhoheit | eigener VPS möglich | OpenAI-Cloud |
| Reife / Stabilität | 3 Monate (Hermes) | Enterprise-grade |
Beide haben ihre Daseinsberechtigung. Hermes plus DeepSeek ist die Werkbank für asynchrone Voice-Workflows, Firmengedächtnis-Zugriff und Recherche-Aufträge – günstig, datensouverän, integrierbar. GPT-Realtime-2 ist die Premium-Lösung, wenn du tatsächlich Konversationen führen willst (z. B. Mock-Interviews, Sprachtraining, mündliche Strategie-Sparring).
Für die meisten Solo-Gründer:innen empfehlen wir, mit Hermes anzufangen. Erst nach vier bis sechs Wochen Praxiserfahrung weißt du, ob du wirklich Echtzeit-Konversation brauchst – oder ob asynchrone Voice-Memos reichen.
10. Konkrete erste Schritte
Nicht alles am ersten Wochenende. Hier der realistische Pfad:
Diese Woche: Phase 0
Auf der Hermes-Website kurz im gehosteten Modus testen. Bauchgefühl entwickeln, ob das Konzept zu dir passt.
Nächstes Wochenende: Phase 1+2
Hetzner-VPS bestellen, Hermes installieren. Erste Konfiguration, einfacher Test mit Text. Noch keine produktive Nutzung.
Übernächstes Wochenende: Phase 3+4
Telegram-Bot anbinden, GitHub-Token mit minimalen Rechten einbinden, erste Voice-Nachricht senden.
Über 2–4 Wochen: Phase 5 iterativ
Skills schreiben, testen, nachschärfen. Bei Fehlern nicht den Output korrigieren, sondern den Skill – so lernt das System dauerhaft.
Nach 4–6 Wochen: Premium-Erweiterungen prüfen
Brauchst du wirklich ElevenLabs-Stimmen? Lohnt sich GPT-Realtime-2 für ergänzende Echtzeit-Konversation? Diese Fragen kannst du fundiert erst beantworten, wenn dein Hermes-Setup vier Wochen produktiv läuft.
⚠ Ehrliche Erwartungs-Setzung
Wer am ersten Wochenende kein flüssiges Gespräch wie bei ChatGPT bekommt, fühlt sich verarscht. Stell dich darauf ein: das ist WhatsApp-Voice-Workflow, nicht „Hey Siri". Das ist nicht schlechter – nur anders. Für die meisten Beratungs-Use-Cases (Notiz, Recherche, Firmengedächtnis-Abfrage) ist asynchron sogar besser, weil du parallel weiterarbeiten kannst.
Quellen & weiterführende Links
Alle in diesem Artikel zitierten Preise, Features und Bug-Berichte sind gegen folgende Original-Quellen geprüft:
- Hermes Agent Docs: Voice Mode (offizielle Doku)
- Hermes Agent Docs: Voice & TTS
- Hermes Agent Docs: Telegram-Integration
- GitHub: NousResearch/hermes-agent (offizielles Repository)
- GitHub Issue #17101: Telegram Voice Messages Not Transcribed (OpenClaw)
- DeepSeek API Docs: Offizielle Preisübersicht
- Anthropic Docs: Claude API Pricing
- OpenAI: Advancing Voice Intelligence in the API (GPT-Realtime-2 Ankündigung)
- OpenAI: API Pricing Übersicht
- Hetzner Cloud: CX-Linie Preise & Specs
- Telegram Bot API – Offizielle Dokumentation